在本节中,我们将深入探讨 OpenRLHF 框架的整体结构和核心组件,了解 PPO 在 RLHF 中的实际应用。以下是 OpenRLHF 整体的代码架构,我们将围绕 PPO 有关的训练脚本、训练器 Trainer、损失函数、模型架构展开讨论。部分内容参考仓库作者的博客:PPO 实现技巧 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 OpenRLHF
主流程入口 train_ppo.py 在 OpenRLHF 框架中,主要的 PPO 训练流程在 cli/train_ppo.py 脚本中实现。该脚本负责模型的初始化、数据加载、训练过程控制等核心功能。
参数列表 一、Checkpoint 相关参数
save_pathstr (./ckpt) 模型保存路径,用于存储训练后的 Actor 模型。 save_stepsint (-1) 保存间隔步数,-1 表示按训练周期(episode)保存。 load_checkpointbool (False) 是否从检查点恢复训练,用于长时间训练任务或调试时中断后继续训练的场景。 max_ckpt_numint (3) 最大保留检查点数量,防止存储空间溢出。
二、PPO 核心参数
策略优化参数 num_episodesint (1) 训练轮次数量,控制整个 PPO 流程的执行次数。 eps_clipfloat (0.2) PPO 的核心超参数,限制新旧策略概率比的剪切范围。越大允许策略变化越大,但可能降低稳定性。 value_clipfloat (0.2) Critic 值函数更新的剪切范围,防止 Critic 网络更新过快。 init_kl_coeffloat (0.01) KL 散度惩罚项的初始系数,约束策略更新幅度,总损失为 policy_loss + value_loss + kl_coef * KL_divergence。 kl_targetfloat (None) 若设置,KL 系数会动态调整以逼近目标值(如 0.01)。自适应 KL 控制可平衡探索与稳定性。 优势估计 gammafloat (1) 折扣因子。1 表示无折扣,接近 0 更关注即时奖励。 lambdfloat (0.95) GAE 的 λ 参数,平衡偏差与方差。1 等价于蒙特卡洛方法(高方差),0 仅用一步 TD 误差(高偏差)。 advantage_estimatorstr (gae) 优势估计方法。gae:基于 Critic 的广义优势估计(需Critic网络); reinforce:蒙特卡洛策略梯度(无 Critic,高方差);rloo:基于多个样本的相对奖励比较(需n_samples_per_prompt>1) 混合训练 ptx_coeffloat (0.05) 预训练损失的权重系数,公式为 total_loss = ppo_loss + ptx_coef * pretrain_loss。
三、模型配置
pretrainstr (None) Actor 模型的预训练权重路径,必需参数。 reward_pretrainstr (None) 奖励模型的预训练权重路径。 critic_pretrainstr (None) Critic 模型的预训练权重路径。 flash_attnbool (False) 启用 FlashAttention-2 加速注意力计算。 bf16bool (False) 使用 bfloat16 混合精度训练,降低显存消耗。
四、优化器参数
actor_learning_ratefloat (1e-6) Actor 网络学习率,通常比 Critic 小一个量级。 critic_learning_ratefloat (9e-6) Critic 网络学习率,需快速适应价值估计。 adam_betasfloat (0.9,0.95) Adam 优化器的 β1/β2 参数,控制动量衰减率。 lr_warmup_ratiofloat (0.03) 学习率预热比例,帮助训练初期稳定收敛。
五、数据集参数
prompt_datastr (None) 提示数据集路径,用于生成阶段采样提示。 pretrain_datastr (None) 预训练数据集路径,用于 PTX 混合训练。 n_samples_per_promptint (1) 每个提示生成的响应数量,影响数据多样性。
六、生成控制
top_pfloat (1.0) Nucleus 采样概率阈值,控制生成多样性。 temperaturefloat (1.0) 温度参数,调整 softmax 分布平滑度。 generate_max_lenint (1024) 生成响应的最大长度,影响计算资源消耗。
七、DeepSpeed 配置
zero_stageint (2) ZeRO 优化阶段,1/2/3 对应不同显存优化级别。 gradient_checkpointingbool (False) 激活梯度检查点,用计算时间换显存空间。
八、LoRA 参数
lora_rankint (0) LoRA 的秩大小,决定低秩矩阵的维度。 lora_alphaint (16) LoRA 缩放系数,控制适配器对原模型的影响强度。
模型加载 在 train.py 中,初始化并加载了 Actor 模型和 Reference 模型用于生成和评估回复(二者的加载方式和路径几乎一样)。通过函数 get_llm_for_sequence_regression 加载 Reward 模型和 Critic 模型。
Actor Model :
在 OpenRLHF 中,Actor 模型负责生成文本动作(即生成的 token 序列)并计算动作的对数概率。Actor 通过 generate 方法调用模型的生成功能,生成文本序列后通过 process_sequences 处理生成结果:
定位有效 Token :通过翻转 attention_mask 并寻找第一个非填充位置,确定每个序列的结束位置(EOS),避免中间填充干扰。掩码生成 :attention_mask 标记有效 Token 范围(首个 Token 到 EOS),action_mask 标记强化学习中需优化的动作位置。序列截断 :根据输入长度 input_len 分割状态序列 state_seq,确保动作与状态的对应关系。Actor 的 forward 方法计算每个动作的对数概率:在处理位置编码后,调用基础模型 self.model 获取 logits,通过 log_probs_from_logits 计算每个 Token 的对数概率,最后提取目标位置的 action_log_probs。
核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 class Actor (nn.Module ): @torch.no_grad() def generate (self, input_ids: torch.Tensor, **kwargs ):return self.process_sequences(sequences, input_ids.size(1 ))def process_sequences (self, sequences: torch.Tensor, input_len ):1 ) - 1 - attention_mask.long().flip(dims=[1 ]).argmax(dim=1 , keepdim=True )1 , index=eos_indices, value=eos_token_id)1 , keepdim=True )1 ), device=sequences.device).expand_as(sequences)return sequences, attention_maskdef forward (self, sequences, num_actions, attention_mask=None ):1 ) - 1 1 ], sequences[:, 1 :])return action_log_probs
Reward Model :
奖励模型通过 _get_reward_model 函数加载。由于在 PPO 训练过程中,奖励模型的参数是冻结的 ,不参与更新,因此可以指定一个预训练好的模型地址 remote_rm_url。需要特别注意的是要准确识别 EOS 标记 ,确保从模型的输出中提取正确的奖励值,即整个序列的得分。
核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class RewardModel (base_pretrained_model ):def forward (self, input_ids, attention_mask ):getattr (self, self.base_model_prefix)("last_hidden_state" ] getattr (self, self.value_head_prefix)(last_hidden_states).squeeze(-1 ) 1 ) - 1 - attention_mask.long().flip(dims=[1 ]).argmax(dim=1 , keepdim=True )1 , index=eos_indices).squeeze(1 ) return reward
在上述代码中,通过翻转 attention_mask 并寻找第一个非填充位置,定位到序列中最后一个有效的 Token 的索引 eos_indices。然后,从模型的输出 values 中提取对应位置的得分,即为该序列的奖励值 reward。
Critic Model :
Critic 模型使用 _get_critic_model 函数加载。由于在 PPO 训练过程中,Critic 模型的参数需要更新 ,因此需要对其进行训练。
在序列生成任务中,Critic 模型需要对序列中每个动作(Token)之后的状态进行价值估计。但需要注意的是,通常不对最后一个时间步(终止状态)的价值进行估计,因为其未来累积奖励一般为零,无需估计。
Critic 模型的核心代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class CriticModel (base_pretrained_model ):def forward (self, input_ids, num_actions, attention_mask ):getattr (self, self.base_model_prefix)("last_hidden_state" ] getattr (self, self.value_head_prefix)(last_hidden_states).squeeze(-1 ) 1 ] return action_values
在上述代码中,values 包含了序列中每个位置的价值估计。通过 values[:, :-1] 去除最后一个时间步的价值估计。随后,使用 num_actions指定要提取的价值数量,即对应于实际动作的价值估计 action_values。
模型训练 通过指定 PPOTrainer,调用 fit 函数,开始模型的训练过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 trainer = PPOTrainer(
接下来,我们将详细解析 PPOTrainer 的实现和训练流程。
PPO Trainer PPOTrainer 是 OpenRLHF 框架中用于实现 PPO 算法的核心模块。它负责管理策略模型的训练过程,使模型能够在与环境交互的过程中不断优化,生成更符合人类偏好的回复。
关键参数解读 strategy :指定训练策略,管理分布式训练、混合精度、模型并行、数据并行等等。
actor 和 critic 的 optimizer 和 scheduler :模型的优化器和学习率调度器。
init_kl_coef :KL 散度的初始系数,用于对 PPO 损失函数中限制策略偏移的 KL 约束项进行加权。
ptx_coef :预训练数据的监督损失权重。在强化学习训练过程中,可以加入少量原始预训练任务的监督损失(PTX),以防止模型遗忘预训练知识,默认为 0。
buffer_limit :回放缓冲区 (replay bufer)最大容量。若使用经验重放机制,存储生成的轨迹数据并用于后续训练,0表示无限制。
eps_clip :策略更新时的裁剪范围,PPO 重要超参数,防止新策略与旧策略概偏离过大。
value_clip :对价值函数更新进行裁剪,防止价值估计在更新过程中发生过大偏移,稳定 Critic 的训练。
gradient_checkpointing :若为 True,在反向传播时重新计算部分前向传播,牺牲计算时间以节约显存。
remote_rm_url :若有远程的 reward model 服务,可通过 URL 访问。
reward_fn :自定义奖励函数,用于根据生成的文本序列为策略分配奖励。
generate_kwargs :策略模型在 rollout 或推理阶段的参数,如 max_length、temperature、top_k、top_p 等。
初始化函数 init 初始化主要完成模型的加载、超参数的设置、优化器和调度器的配置,以及损失函数的定义等。具体包括:
损失函数 :actor_loss_fn: 策略损失函数,使用 PPO 的裁剪策略。critic_loss_fn: 价值损失函数,使用价值裁剪。ptx_loss_fn: 预训练任务的损失函数(如语言模型的交叉熵损失)。经验和重放缓冲区 :experience_maker:经验生成器,用于与环境交互,生成训练所需的样本数据,包括状态、动作、奖励、优势等信息。replay_buffer:重放缓冲区,用于存储和采样训练数据。循环层级解读 初始化后,会进入 PPOTrainer 的核心训练循环,在这里需要先理清楚循环层级的概念:
Episode :一个完整的 PPO 训练周期,通常包含「经验收集」和「模型更新」两个流程,每个 Episode 会遍历所有 Prompt(num_episodes)。Batch :分别表示两个流程中的批处理样本数量。Rollout Batch :每次生成经验时并行处理的提示数量(rollout_batch_size),并且由于每个 Prompt 会采样 n_samples_per_prompt 个响应,二者相乘就是 replay_buffer 的大小。Train Batch :每次参数更新时使用的经验子集(train_batch_size),通常会更小,因为训练需要的显存较大。例如同时用 32 个提示生成响应后,每次梯度下降用 8 条经验计算损失。Epoch :对当前收集的一批经验数据重复训练的轮数(max_epochs)。一批经验会重复被利用多次(每次都会打乱顺序),但不需要重新计算优势等信息,都会存储在 buffer 中。Step :既表示参数更新步,又表示环境交互步。Update Step :参数更新步,每个 Step 会更新一次 Actor 和 Critic Model,是一次参数更新的最小单位,对应一个 Train Batch 的处理(training_step)。Global Step :环境交互步,表示 Episode 中的 Rollout 次数,用于跟踪训练进度,有时候 Actor 会先冻结一些步骤,就需要用这个变量来区分不同阶段(global_steps)。下图展示了各个层级的关系:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Episode 1
拟合函数 fit fit 函数是 PPOTrainer 的核心训练循环,主要包括以下步骤:
训练状态恢复 :在中断训练后,可以根据已消耗的样本数恢复训练步数和起始的 episode,以继续未完成的训练过程。主训练循环 :遍历每个训练 epoch,在每个 epoch 中执行以下操作:数据加载 :从数据加载器(prompts_dataloader)中获取随机的提示(prompts)。收集经验 :使用 experience_maker 生成经验数据。将生成的经验数据添加到重放缓冲区中。PPO 训练过程 :进行 loss 的计算与参数更新。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 def fit ():1 for episode in range (start_episode, args.num_episodes):for rand_prompts in self.prompts_dataloader:for i, experience in enumerate ("advantages" , self.strategy)
训练函数 ppo_train ppo_train 函数负责具体的训练过程,主要包括以下步骤:
主训练循环 ppo_train:控制训练的 epoch 和 train_batch,遍历当前批次的经验数据 batch_experiences 用 training_step 执行每个训练步骤。训练步骤 training_step:根据当前的全局步数 global_steps,决定是否训练 actor 和 critic 模型训练策略模型 training_step_actor:计算策略损失,并更新策略网络的参数。 训练价值模型 training_step_critic:计算价值损失,并更新价值网络的参数。 1 2 3 4 5 6 7 8 9 10 11 12 13 def ppo_train (self, global_steps=0 ):for epoch in range (max_epochs):for experience in batch_experiences: def training_step (self, experience, global_steps ) -> Dict [str , float ]:return status
模型更新 更新 Actor training_step_actor 负责 Actor Model 的更新,主要包括以下步骤:
训练模式切换 :设置 Actor 网络为训练模式,启用 dropout 等训练专用模块经验数据准备 :将传入的经验数据拆为轨迹序列 sequences、旧策略概率 old_action_log_probs(用于重要性采样计算)、优势值 advantages 等。策略网络前向推理 :通过 Actor 模型计算当前策略的动作概率分布 \(\pi_\theta\left(a_t \mid s_t\right)\) 。策略损失计算和更新 :根据前面计算的结果调用损失函数,更新。这里还可以选择加上混合预训练更新 。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 def training_step_actor (self, experience ):1 )if self.pretrain_dataloader is not None :next (self.pretrain_dataloader)True )"logits" ]"actor" )return status
更新 Critic training_step_critic 负责 Critic Model 的更新,主要步骤和前面的类似,不再赘述。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 def training_step_critic (self, experience ):1 )None "critic" )return status
损失函数 loss.py 在 PPO trainer 的 init 函数中,分别加载了策略模型 损失函数、价值模型 损失函数、语言模型 损失函数,用于优化 Actor、Critic 和防止模型遗忘预训练知识。接下来我们一一分析:
1 2 3 self.actor_loss_fn = PolicyLoss(eps_clip)
策略模型损失函数 (Policy Loss) 用于优化 Actor 模型,为确保策略更新不会偏离旧策略太远,通过计算新旧策略的概率比率,并使用裁剪参数 \(\epsilon\) 与裁剪函数 clamp 限制更新幅度,从而稳定训练过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class PolicyLoss (nn.Module ):def forward ( self, log_probs: torch.Tensor, old_log_probs: torch.Tensor, advantages: torch.Tensor, action_mask: Optional [torch.Tensor] = None , ) -> torch.Tensor:1 - self.clip_eps, 1 + self.clip_eps) * advantages min (surr1, surr2) 1 ).mean() return loss
价值模型损失函数 (Value Loss) 用于优化 Critic 模型,其目标是最小化当前价值的估计与目标价值之间的差值 ,从而使得 Critic 模型能够准确拟合真实的回报 ,即 \(L^{\text{Critic}}(\phi) = \mathbb{E}_{(x, y) \sim \mathcal{D}} \left[ \| V_\phi(x) - \hat{R}(x, y) \|^2 \right]\) 。
虽然在 PPO 原论文中并未对价值函数引入裁剪,但在一些 PPO 的变体中,为了提高训练的稳定性,也在价值函数的训练中引入了裁剪操作。同样,通过参数 \(\epsilon\) ,约束新策略 \(V_\phi^{new}\) 与旧策略 \(V_\phi^{old}\) 之间的变化幅度。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class ValueLoss (nn.Module ):def forward ( self, values: torch.Tensor, old_values: torch.Tensor, returns: torch.Tensor, action_mask: Optional [torch.Tensor] = None , ) -> torch.Tensor:if self.clip_eps is not None : 2 2 max (surr1, surr2) else :2 1 ).mean() return 0.5 * loss
注意:在优化价值函数时,采用了 torch.max(surr1, surr2) 来选择较大的损失值,这与策略模型损失函数中使用 torch.min(surr1, surr2) 的方式不同。
这是因为:
策略损失函数 :在策略更新中,我们的目标是让 \(r_t(\theta)\) 趋向于 \(1\) ,因此仅当 \(\pi_\theta\) 远离 \(\pi_{\theta_\text{old}}\) 时,我们需要缩小更新的幅度;而当 \(\pi_\theta\) 靠近 \(\pi_{\theta_\text{old}}\) 时,则不需要缩小。价值损失函数 :在价值更新中,我们的目标是让 \(V_\phi\) 趋向于 \(V_t^{\text{target}}\) ,因此无论 \(V_\phi\) 偏离 \(V_{\phi_\text{old}}\) 多少都不需要缩小,但如果 \(V_\phi\) 离目标越远,则其 Loss 越大,更新的速度也就越快,此时就需要选最大者。这里的 CLIP 操作只是单纯为了多一种选择 (且这个选择比较靠谱,因为离 \(V_{\phi_\text{old}}\) 不太远)。语言模型损失函数 (GPTLM Loss) GPT 语言模型损失函数用于预测序列中的下一个 token。通过移位操作,模型基于前面的 token 预测下一个 token。使用交叉熵损失函数来计算预测与真实标签之间的误差。
1 2 3 4 5 6 7 8 9 10 11 12 class GPTLMLoss (nn.Module ):def __init__ (self ):100 def forward (self, logits: torch.Tensor, labels: torch.Tensor ) -> torch.Tensor:1 , :].contiguous() 1 :].contiguous() 1 , shift_logits.size(-1 )), shift_labels.view(-1 ))return loss
奖励模型损失函数(PairWise Loss) 奖励模型的损失函数用于比较两个生成结果的优劣。在前文 Reward Model 介绍中 Pairwise loss 的计算方式为,\(L^{\text{RM}}= -\log \sigma(r_\text{chosen} - r_\text{reject})\) 。通过 sigmoid 函数将奖励差异映射到 \((0,1)\) 区间,然后取负对数。在实现过程中,margin 参数可以用于强化区分度,即不仅要求 \(y_\text{chosen} > y_\text{reject}\) ,还要求 \(y_\text{chosen} > y_\text{reject} + margin\) 。
1 2 3 4 5 6 7 8 9 class PairWiseLoss (nn.Module ):def forward ( self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor, margin: torch.Tensor = None ) -> torch.Tensor:if margin is not None :else :return loss.mean()
第二种计算方法同样是比较两个生成结果优劣的奖励模型损失,在公式上是上述实现的等价变换 \(-\log(\mathrm{sigmoid}(x)) = \log(1+e^{-x})\) 。当 \(r_\text{reject} - r_\text{chosen}\) 为负值(即选中的序列更好)时,损失接近 0;当 \(r_\text{reject} - r_\text{chosen}\) 为正值时,损失随差值线性增长。
1 2 3 4 5 6 class LogExpLoss (nn.Module ):def forward ( self, chosen_reward: torch.Tensor, reject_reward: torch.Tensor, margin: torch.Tensor = None ) -> torch.Tensor:1 + torch.exp(reject_reward - chosen_reward)).mean()return loss
过程奖励模型损失函数(PRMLoss) 在强化学习的奖励建模中,传统的奖励模型往往只评估完整序列的好坏。然而,在一些复杂任务中,我们希望模型能够对生成过程中的每个步骤进行评估,这就引入了过程奖励模型(Process Reward Model,PRM)。PRM 能够对生成序列中的每个步骤打分,以更细粒度地指导模型的生成过程。
PRM 的损失函数旨在学习模型对每个步骤的奖励评估 。具体的实现方式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 class PRMLoss (nn.Module ):def __init__ (self, placeholder_token_id: int , reward_token_ids: Optional [list [int ]] = None ):super ().__init__()100 def forward (self, inputs: torch.Tensor, logits: torch.Tensor, labels: torch.Tensor, *, return_acc: bool = False ):if labels.dtype == torch.float :assert len (self.reward_token_ids) == 2 , "reward_token_ids should have 2 tokens for soft labels" 1 - positive_labels 1 ) elif self.reward_token_ids is not None :for i, token in enumerate (self.reward_token_ids):if not return_acc:return lossif labels.dtype == logits.dtype:1 )1 ) == labels).float ().mean()return loss, acc
我们以一个 PRM 数据集的示例来说明:
1 2 3 4 5 {"inputs" : "Janet pays $40/hour for 3 hours per week of clarinet lessons and $28/hour for 5 hours a week of piano lessons. How much more does she spend on piano lessons than clarinet lessons in a year? Step 1: Janet spends 3 hours + 5 hours = <<3+5=8>>8 hours per week on music lessons. ки Step 2: She spends 40 * 3 = <<40*3=120>>120 on clarinet lessons per week. ки Step 3: She spends 28 * 5 = <<28*5=140>>140 on piano lessons per week. ки Step 4: Janet spends 120 + 140 = <<120+140=260>>260 on music lessons per week. ки Step 5: She spends 260 * 52 = <<260*52=13520>>13520 on music lessons in a year. The answer is: 13520 ки" ,"labels" : "Janet pays $40/hour for 3 hours per week of clarinet lessons and $28/hour for 5 hours a week of piano lessons. How much more does she spend on piano lessons than clarinet lessons in a year? Step 1: Janet spends 3 hours + 5 hours = <<3+5=8>>8 hours per week on music lessons. + Step 2: She spends 40 * 3 = <<40*3=120>>120 on clarinet lessons per week. + Step 3: She spends 28 * 5 = <<28*5=140>>140 on piano lessons per week. + Step 4: Janet spends 120 + 140 = <<120+140=260>>260 on music lessons per week. + Step 5: She spends 260 * 52 = <<260*52=13520>>13520 on music lessons in a year. The answer is: 13520 -" ,"values" : [ "+" , "+" , "+" , "+" , "-" ]
在这个例子中:
inputs:每个步骤后面都有一个特殊标记 ки,用于标记步骤的结束位置。labels:每个步骤后面有一个标签 + 或 -,表示当前步骤的推理是否正确。当使用软标签 (Soft Labels)时,每个步骤的标签是不再是 id,而是一个 float 概率值,比如 [0.8, 0.85, 0.9, 0.78, 0.1],表示该步骤为正样本的概率。在代码中的实现为:
placeholder_token_id 标记每个步骤结束位置的特殊标记的 ID,用于定位需要评估的步骤位置。reward_token_ids 用于表示奖励的标签 token ID 列表,比如 ['+', '-'] 对应的 token IDs。也可以有更多的标签进行多分类,但在使用软标签 时只支持二分类。experience_maker 类在强化学习中,经验 (experience)是指智能体与环境交互时收集的数据。这些数据通常以元组形式表示 \((s_t, a_t, r_t, s_{t+1})\) ,包括智能体采取的动作、所处的状态、获得的奖励以及下一个状态。
OpenRLHF 框架中定义了一个 NaiveExperienceMaker 类,其核心函数 make_experience_list 实现了从提示(prompt)生成响应(response),构建样本(samples),处理经验(experience),以及计算奖励和优势的完整流程。接下来,我们将按照这一流程,逐步解析各部分的实现。
采样并构建 Samples 为了方便管理和操作,框架中定义了一个 Samples 类,用于存储生成过程中的响应和相关信息,例如响应长度、注意力掩码(attention_mask)和动作掩码(action_mask)等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @dataclass class Samples :"""Samples is a batch of data. "B" 是批次大小。 "S" 是序列长度。 "A" 是动作的数量,即生成的token长度 """ Optional [torch.LongTensor] Optional [torch.BoolTensor] Union [int , torch.Tensor] Optional [torch.Tensor]
通过 generate_samples 收集每个属性,构建 samples。
1 samples_list = self.generate_samples(all_prompts, **generate_kwargs)
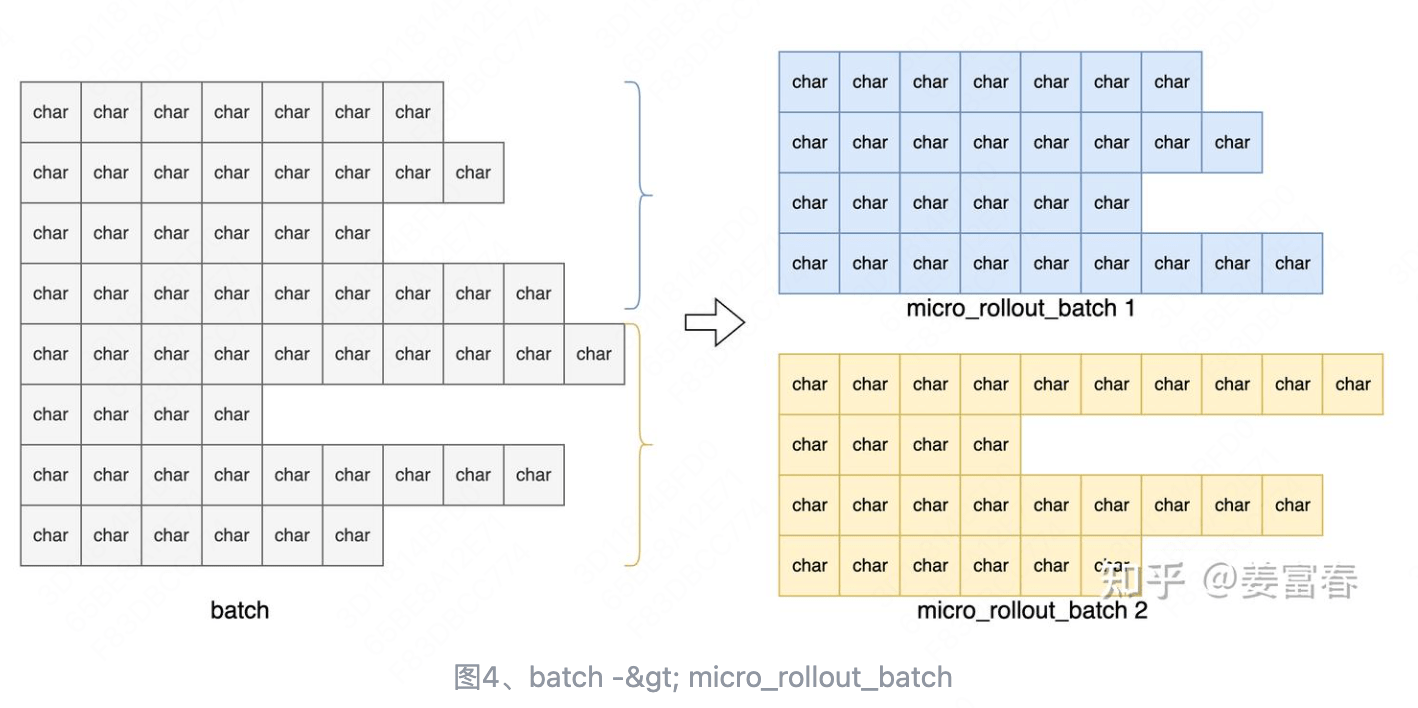
首先,基于 args.micro_rollout_batch_size 的配置,将数据进行批处理。
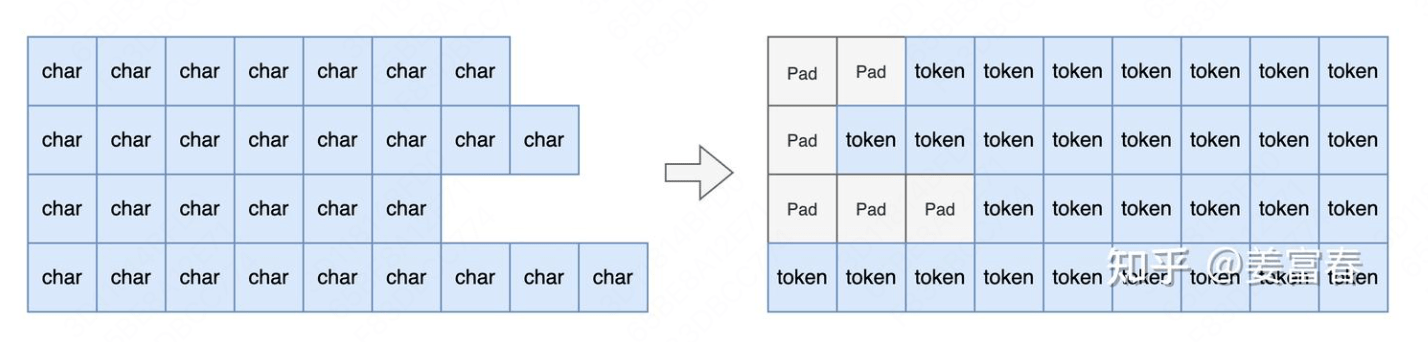
然后,调用 tokenize_fn,将 Prompt 进行 token 化,并进行左 padding 处理。
接下来,调用 Actor.generate() 方法,根据给定的提示 input_ids 生成包含提示和响应的完整序列 sequences,同时生成 attention_mask 和 action_mask。
1 sequences, attention_mask, action_mask = self.actor.generate(**inputs, **generate_kwargs)
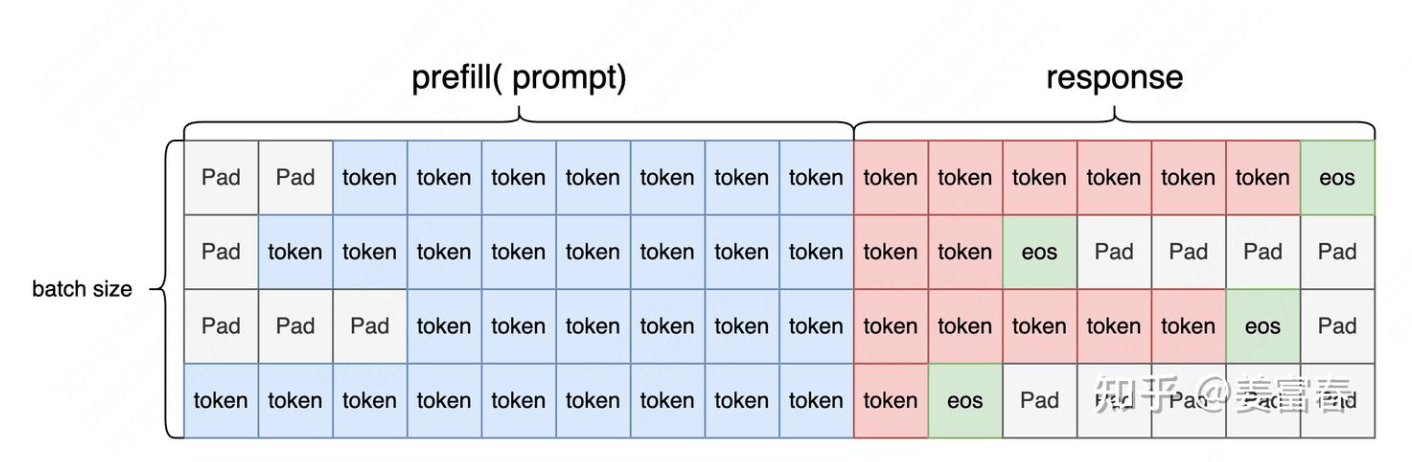
sequences:形状为 (B, S),包含了 Prompt 和生成的 Response 的拼接序列。
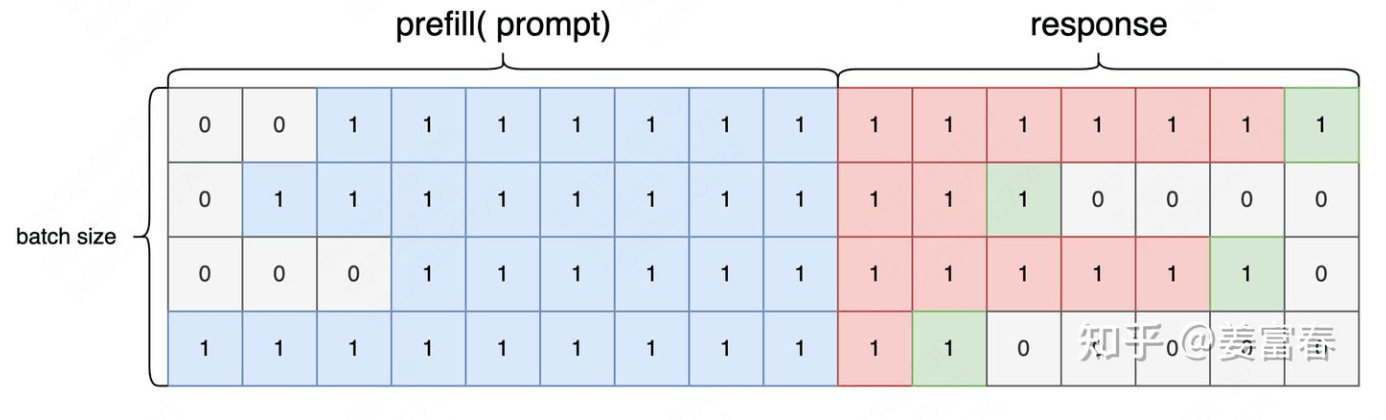
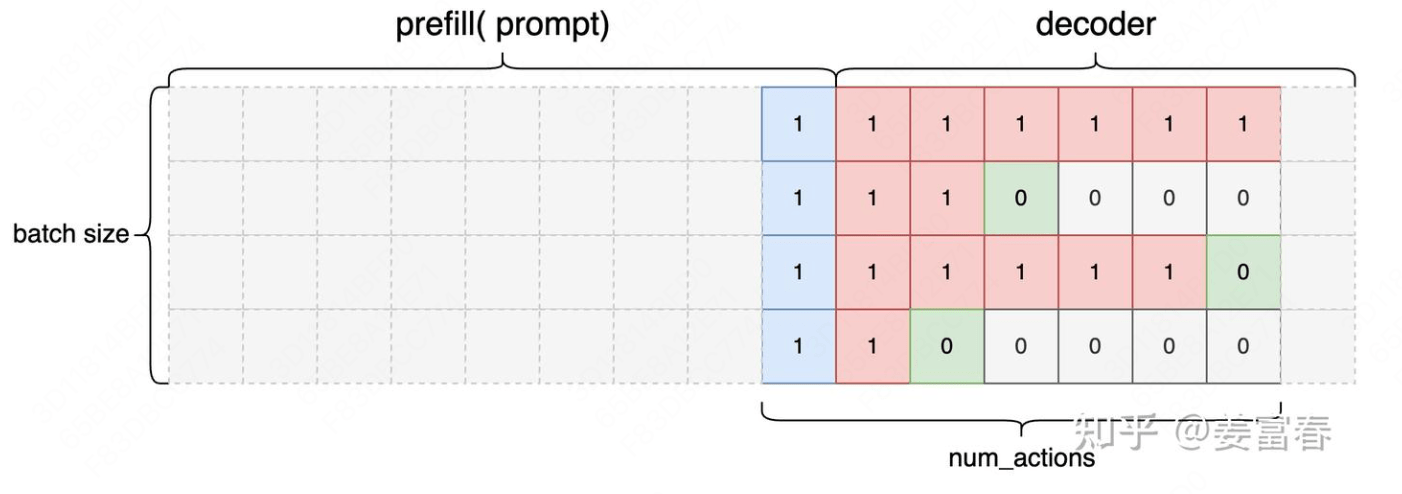
attention_mask:形状为 (B, S),用于标记序列中哪些位置是有效的,将填充(padding) 部分置为1,在计算时忽略。1 attention_mask = (mask >= first_token_indices) & (mask <= eos_indices).to(dtype=torch.long)
action_mask:形状为 (B, A),也就是序列长度是生成的 token 数,num_actions。对有效状态位置值1,用于区分 Prompt 和 Response 部分,标记 Response 部分的动作,用于后续的策略优化。1 2 3 state_seq = sequences[:, input_len - 1 : -1 ]0 ] = 1
通过以上步骤,我们构建了一个包含序列数据和相关掩码信息的 Samples 对象,为后续的经验处理做好了准备。
处理 Samples 构建 Experience 生成了 Samples 后,需要对其进行进一步处理,计算每个动作的对数概率、价值估计和 KL 散度等信息,构建强化学习所需的 Experience 对象。Experience 类在 Samples 的基础上,增加了价值估计(values)、回报(returns)和优势(advantages)等信息,用于强化学习的训练。
1 2 3 4 5 6 7 8 9 10 11 class Experience :"""Experience is a batch of data. """ Optional [torch.Tensor] Optional [torch.Tensor] Optional [torch.LongTensor] Optional [torch.BoolTensor] Optional [torch.Tensor] = None
在处理过程中,调用 make_experience 函数,计算得到强化学习训练所需的经验数据:对数概率(logprobs) 、价值(values) 、奖励(rewards) ,以及 KL 散度(kl divergence) 。这里的 reward 代表一个交互轨迹的总分。advantage 和 return 两个元素在后续步骤计算。
1 2 3 4 5 6 7 8 9 10 11 12 13 def make_experience (self, samples: Samples ) -> Experience:return Experience(...)
处理经验数据 process_experiences 函数用于对经验数据进行进一步处理。当使用 RLOO 作为优势估计器时,需要对奖励进行 Leave-One-Out 处理(Reward Shaping)。并且得到 RM 给出的 reward,这里的维度还是 [B, 1]。
1 experiences, rewards = self.process_experiences(experiences)
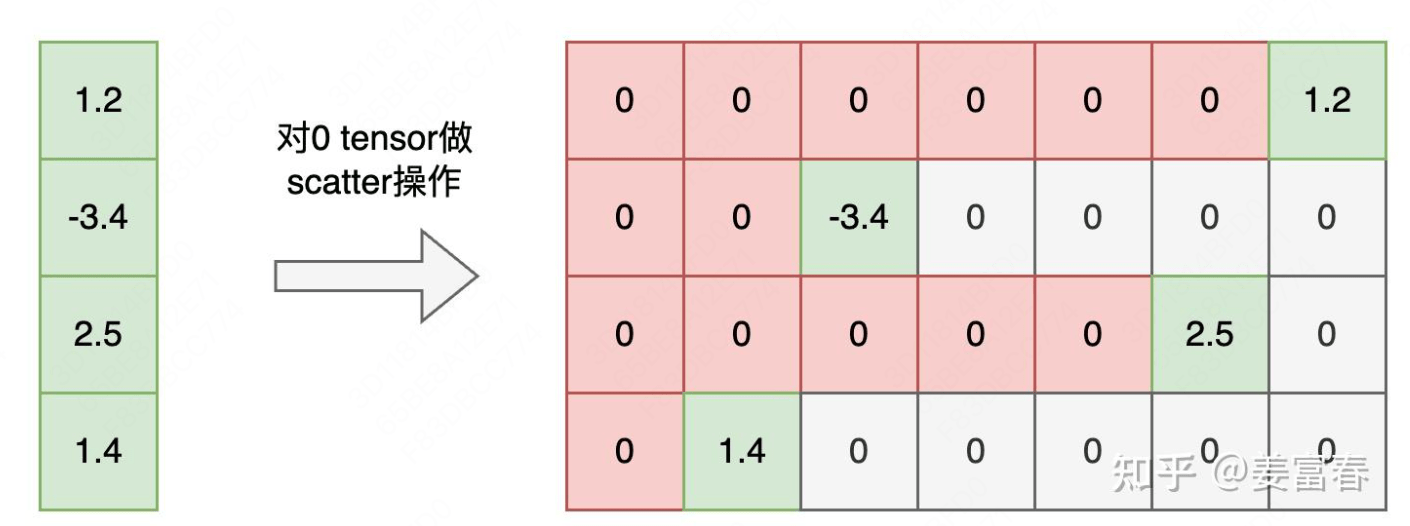
计算每个时间步的奖励 :compute_reward 函数前面步骤中,rewards 是由奖励模型给出的,每个样本只提供了一个最终总奖励 。但是,在强化学习中,策略优化需要每个时间步的奖励。为了在时间步上进行策略优化,我们需要将总奖励分配到每个时间步。
compute_reward 函数的作用是将总奖励分配到序列的特定时间步(通常是最后一个有效动作),并结合 KL 散度惩罚,计算得到每个时间步的总奖励序列。输出的 reward 是一个与动作序列长度匹配的张量,维度是 [B, A]。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def compute_reward ( r: Union [torch.Tensor, float ], kl_coef: float , kl: Union [torch.Tensor, list [torch.Tensor]], action_mask: Optional [torch.Tensor] = None , num_actions: Optional [Union [int , list [int ]]] = None , Union [torch.Tensor, list [torch.Tensor]]:if action_mask is not None :1 ) - 1 - action_mask.long().fliplr().argmax(dim=1 , keepdim=True )1 , index=eos_indices, src=r.unsqueeze(1 ).to(kl.dtype))else :for i, (kl_seg, action_len) in enumerate (zip (kl, num_actions)):1 ] += r[i] return reward
Scatter 操作如下:
这里可选的一个操作是在每个时间步(上图红色位置)加上 KL 惩罚,得到所谓的 \(r_\text{total}\) 。计算得到的每个时间步 的最终 rewards 仅用于后续的优势函数和回报 的计算。
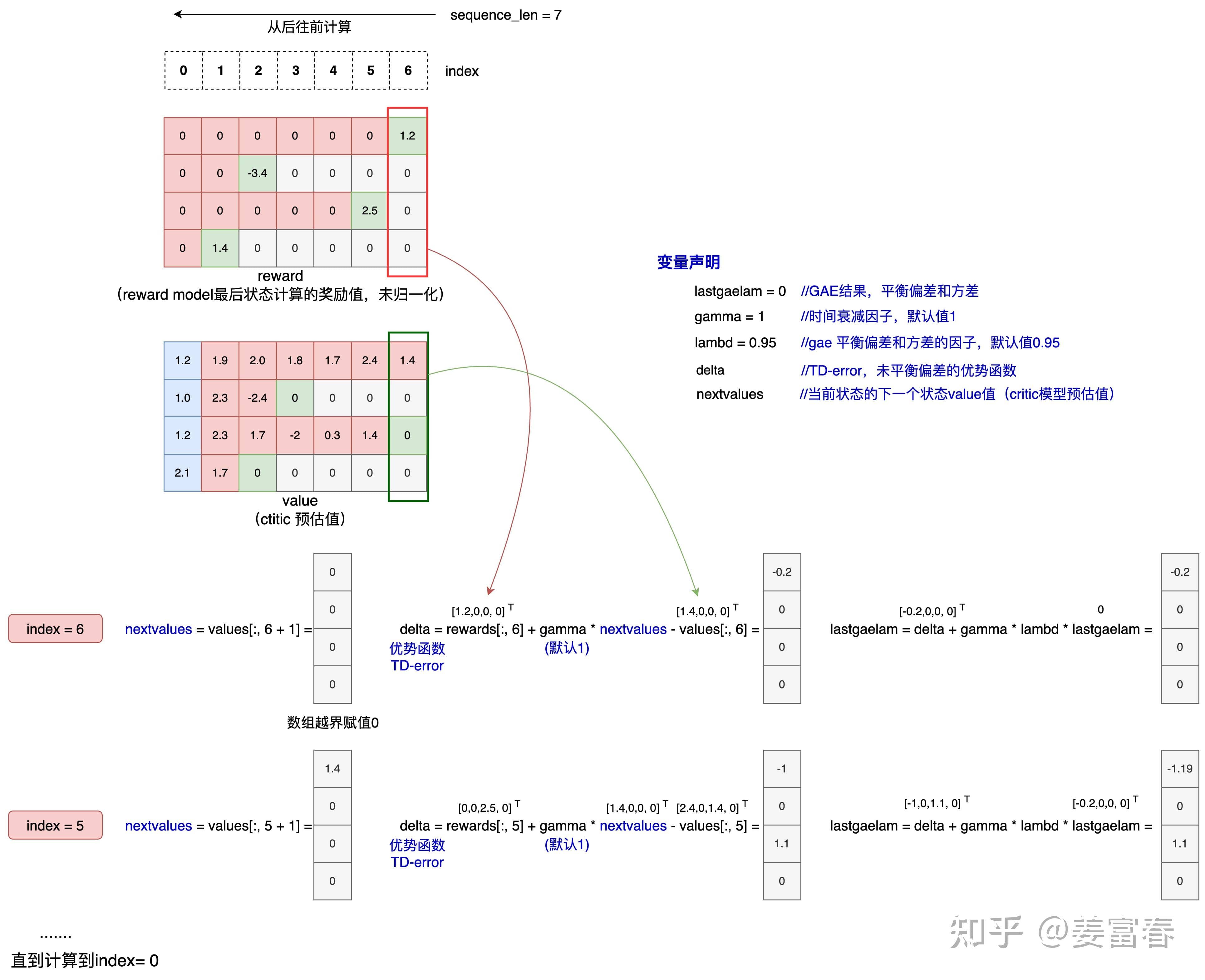
计算优势和回报 在强化学习中,为了更新策略,我们需要计算每个时间步的优势 (advantages)和回报 (returns),用于指导 Actor 和 Critic 的改进。在代码实现中,有两种计算优势和回报的方法:GAE 和 REINFORCE 。
第一种 GAE 算法 通过 get_advantages_and_returns 函数实现,在 PPO 训练中广泛使用。优势计算公式为 $ {t}^{(,)}= {l=0}() l_{t+l}. \(,通过计算每个时间步的时间差分误差(TD error):\) t=r_t+V(s {t+1})-V(s_t)$,递归计算得到优势,最后计算回报 \(R_t = \hat{A}_{t}^{\mathrm{GAE}(\gamma,\lambda)} + V(s_t)\) 。实现代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def get_advantages_and_returns (self, values, rewards, action_mask, gamma, lambd ):0 1 )if action_mask is not None :for t in reversed (range (response_length)):1 ] if t < response_length - 1 else 0.0 1 ], dim=1 ) return advantages.detach(), returns
另一种方法是使用 REINFORCE 算法,无需 Critic Model 直接计算累积回报用于策略的更新。回报 \(R_t\) 定义为从时间步 \(t\) 开始的折扣累积奖励 \(R_t=\sum_{k=0}^{\infty}\gamma^kr_{t+k}\) 。实现代码如下:
1 2 3 4 5 6 def get_cumulative_returns (self, rewards, action_mask, gamma ):for t in reversed (range (response_length)): return returns
通过以上步骤,函数完整地构建了强化学习算法中的经验数据,并计算了策略优化所需的关键量。这些数据将用于后续的策略更新。