ML学习笔记 #05 过拟合与正则化
本文最后更新于:2022年11月16日 中午
在介绍多元线性回归时,我们知道线性回归并不适用于所有情形,因此可以人为构造高阶项并将其当作一个新的特征来使用,从而达到拟合非线性数据的目的,即多项式回归(Polynomial Regression)。
与此同时,由多项式插值的原理可知,我们可以构造一个唯一的 \(m-1\) 次多项式,使其完美地经过 \(m\) 个样本点: \[ L_{n}(x)=\sum_{i=0}^{n} f\left(x_{i}\right) l_{i}(x)=\sum_{i=0}^{n} f\left(x_{i}\right) \prod_{j=0 \atop j \neq i}^{n} \frac{x-x_{j}}{x_{i}-x_{j}} \] 上式即为 Lagrange 插值公式,\(f(x_i)\) 是每个样本的函数值。但这样得到的结果会是好的拟合吗?
过拟合 | Over-Fitting
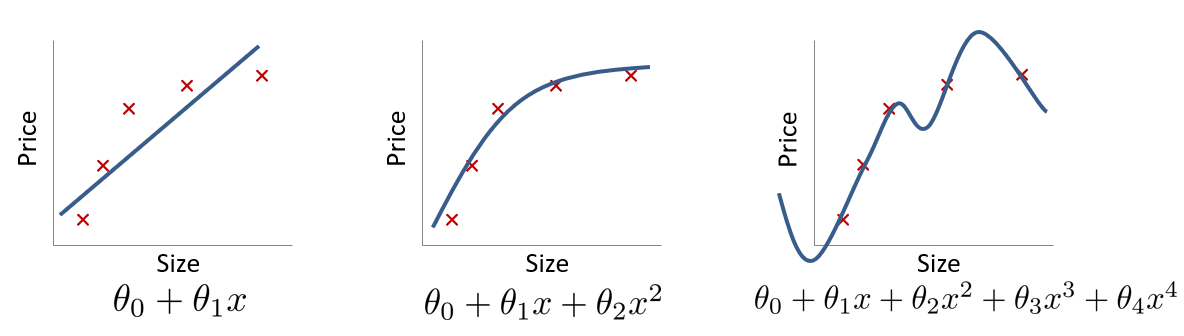
所谓过拟合,一般是指过度在训练集上进行优化,进而损害了测试集上的泛化能力(generalize)的现象,具有高方差(high variance),对输入的变化更敏感。与之对应的概念是欠拟合(Under-Fitting),不能很好地适应训练集,使得算法具有高偏差(high bias)。
下图就是一个典型的回归案例:
分类案例中也存在这样的问题:
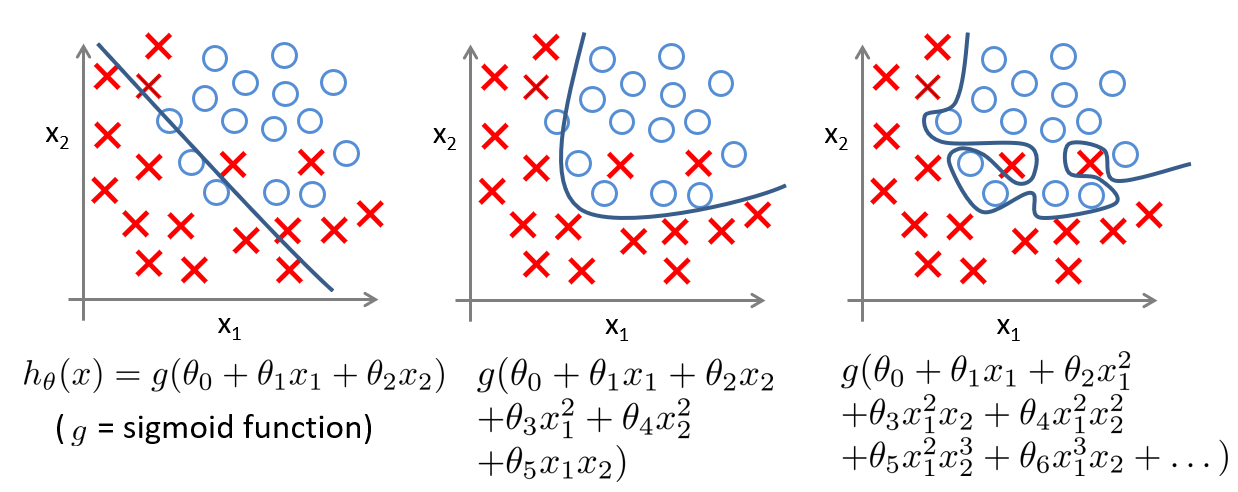
解决过拟合的方法有很多,我将其分为三个层面:
- 从模型层面,可以通过 Early Stop、L1/L2 Regularization、Batchnorm、Dropout 等方法;
- 从特征层面,可以丢弃一些不能帮助我们正确预测的特征,通过手工筛选或 PCA 等降维方法;
- 从数据层面,可以获取更大的数据集,也可以进行数据增强(Data Augmentation),通过一定规则来扩充数据。
正则化 | Regularization
正则化是一种能够保留所有特征(不必降维而丢失信息)的有效解决过拟合的方法。其思想是在损失函数上加上某些规则(限制),限制参数的解空间,从而减少求出过拟合参数的可能性。
仍然以多项式回归为例,如果我们的假设函数为:\(h_\theta(x)=\theta_0+\theta_1x+\theta_2x^2+\theta_3x^3+\theta_4x^4\),其中的高阶项 \(\theta_3,\theta_4\) 导致了过拟合问题,那么我们自然希望 \(\theta_3\) 和 \(\theta_4\) 越小越好。此时,我们只需要对代价函数做出一点修改: \[ J(\theta)=\frac{1}{2m}\left[\sum\limits_{i=1}^m\left(h_\theta(x^{(i)})-y^{(i)}\right)^2+1000\theta_3^2+10000\theta_4^2\right] \] 这样当 \(J(\theta)\) 取得极值时,\(\theta_3\) 和 \(\theta_4\) 都接近于 \(0\),我们也就达到了目的。一般地,我们并不知道究竟应该对哪些参数做出「惩罚」,所以我们设代价函数为: \[ J(\theta)=\frac{1}{m}\sum_{i=1}^m\text{Cost}\left(h_\theta(x^{(i)})-y^{(i)}\right)+\frac{\lambda}{2m}\sum_{j=1}^n\theta_j^2 \] 其中,\(\lambda\) 是正则化参数,\(\lambda\sum\limits_{j=1}^n\theta_j^2\) 是正则化项。即我们对除了 \(\theta_0\) 以外的参数都做「惩罚」,使得曲线更加光滑。如果 \(\lambda\) 很大,意味着正则化项占主要地位,有可能导致所有的 \(\theta_j\) 都太小了而欠拟合;如果 \(\lambda\) 很小,意味着损失函数占主要地位,就有可能过拟合。因此选取合适的正则化参数 \(\lambda\) 是非常重要的,通常要建立验证集进行网格搜索。
为什么不对 \(\theta_0\) 正则化?因为 \(\theta_0\) 是人为设置的偏置项,对于输入的变化(训练集 or 测试集)是不敏感的,不对模型的方差产生贡献,即使发生了过拟合,那也与 \(\theta_0\) 无关。
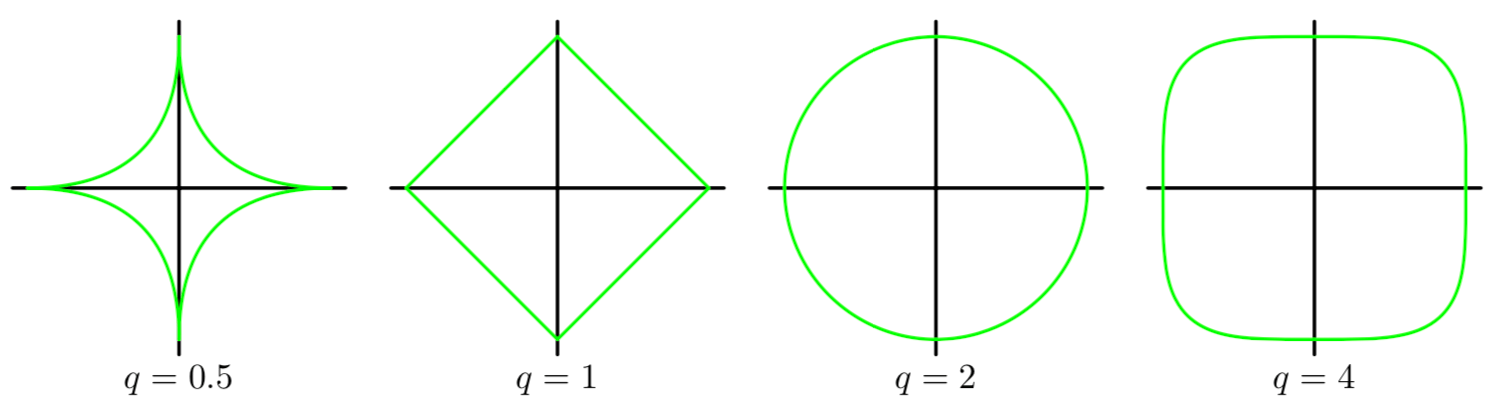
此外,根据正则项的形式,又可分为:二次正则项、一般正则项。二次正则项即为前文提到的形式,更一般的形式为 \(\lambda \sum_{j=1}^n{\left| \theta _j \right|^q}\),当 \(q\) 取不同值等高线图的形状为:
从几何空间上来看,损失函数的碗状曲面和正则化项的曲面叠加之后,就是我们要求极值的曲面。特别地,当 \(q=1\) 时,称其为 L1 正则化,也叫 Lasso 回归;当 \(q=2\) 时,称其为 L2 正则化,也叫岭回归。L2 由于其处处可微的特性,在实际中更常用。
线性回归的正则化
线性回归的含有正则化项的代价函数为: \[ \begin{aligned} J(\theta )&=\frac{1}{2m}\left[ \sum_{i=1}^m{\left( h_{\theta}(x^{(i)})-y^{(i)} \right) ^2}+\lambda \sum_{j=1}^n{\theta _{j}^{2}} \right]\\ &=\frac{1}{2m}\left[ \sum_{i=1}^m{\left( \theta ^Tx^{(i)}-y^{(i)} \right) ^2}+\lambda \sum_{j=1}^n{\theta _{j}^{2}} \right]\\ \end{aligned} \] 对其求导: \[ \frac{\partial J}{\partial \theta_j}=\frac{1}{m}\sum_{i=1}^m\left(\theta^Tx^{(i)}-y^{(i)}\right)x^{(i)}_j+[j\neq 0]\frac{\lambda}{m}\theta_j,\quad j=0,1,\cdots,n \] 所以梯度下降时,整个迭代更新过程为: \[ \begin{aligned} \theta _0:&=\theta _0-\alpha \frac{\partial J}{\partial \theta _j}\\ &=\theta _0-\alpha \frac{1}{m}\sum_{i=1}^m{\left( \theta ^Tx^{(i)}-y^{(i)} \right)}x_{0}^{(i)}\\ \theta _j:&=\theta _j-\alpha \frac{\partial J}{\partial \theta _j}\\ &=\theta _j-\alpha \left[ \frac{1}{m}\sum_{i=1}^m{\left( \theta ^Tx^{(i)}-y^{(i)} \right)}x_{j}^{(i)}+\frac{\lambda}{m}\theta _j \right]\\ &=\theta _j\left( 1-\alpha \frac{\lambda}{m} \right) -\alpha \frac{1}{m}\sum_{i=1}^m{\left( \theta ^Tx^{(i)}-y^{(i)} \right)}x_{j}^{(i)},\quad j=1,\cdots ,n\\ \end{aligned} \] 相当于每次迭代先将参数 \(\theta_j\) 缩小一点,再做原来的梯度下降。除了梯度下降,我们还可以直接用正规方程,即在数学上解它。为了记号的方便,我们先假定对 \(\theta_0\) 也进行「惩罚」。首先将 \(J(\theta)\) 写作矩阵形式: \[ \begin{aligned} J(\theta )&=\frac{1}{2m}\left[ \left( X\theta -y \right) ^T\left( X\theta -y \right) +\lambda \theta ^T\theta \right]\\ &=\frac{1}{2m}\left[ \theta ^TX^TX\theta -\theta ^TX^Ty-y^TX\theta +y^Ty+\lambda \theta ^T\theta \right] \end{aligned} \] 再用 矩阵的求导法则,然后令 \[ \frac{\partial J}{\partial \theta}=\frac{1}{m}\left[X^TX\theta-X^Ty+\lambda\theta\right]=0 \] 则: \[ (X^TX+\lambda)\theta=X^Ty \] 解得: \[ \theta=(X^TX+\lambda)^{-1}X^Ty \] 现在把 \(j=0\) 的特殊情况考虑进去,那么最后的结果就是: \[ \theta =\left( X^TX+\lambda \left[ \begin{matrix} 0 & & & \\ & 1 & & \\ & & \ddots & \\ & & & 1 \\ \end{matrix} \right] _{n+1} \right) ^{-1}X^Ty \]
之前我们曾讨论过 \(X^TX\) 不可逆的情形,但在加入正则化项后,只要 \(\lambda >0\),就一定可逆。
逻辑回归的正则化
逻辑回归的含有正则化项的代价函数为: \[ \begin{aligned} J(\theta )&=-\frac{1}{m}\sum_{i=1}^m{\left[ y^{\left( i \right)}\ln \left( h_{\theta}\left( x^{\left( i \right)} \right) \right) +\left( 1-y^{\left( i \right)} \right) \ln \left( 1-h_{\theta}\left( x^{\left( i \right)} \right) \right) \right]}+\frac{\lambda}{2m}\sum_{j=1}^n{\theta _{j}^{2}}\\ &=\frac{1}{m}\sum_{i=1}^m{\left[ y^{(i)}\ln \left( 1+e^{-\theta ^Tx^{(i)}} \right) +\left( 1-y^{(i)} \right) \ln \left( 1+e^{\theta ^Tx^{(i)}} \right) \right]}+\frac{\lambda}{2m}\sum_{j=1}^n{\theta _{j}^{2}}\\ \end{aligned} \] 同样地,对其求导: \[ \frac{\partial J}{\partial \theta_j}=\frac{1}{m}\sum_{i=1}^m\left(h_\theta(x^{(i)})-y^{(i)}\right)x^{(i)}_j+[j\neq 0]\frac{\lambda}{m}\theta_j,\quad j=0,1,\cdots,n \] 同样地,梯度下降时,整个迭代更新过程为: \[ \begin{aligned} \theta _0&:=\theta _0-\alpha \frac{1}{m}\sum_{i=1}^m{\left( h_{\theta}(x^{(i)})-y^{(i)} \right)}x_{0}^{(i)}\\ \theta _j&:=\theta _j\left( 1-\alpha \frac{\lambda}{m} \right) -\alpha \frac{1}{m}\sum_{i=1}^m{\left( h_{\theta}(x^{(i)})-y^{(i)} \right)}x_{j}^{(i)},\quad j=1,\cdots ,n\\ \end{aligned} \]
代码实现
实现线性回归的正规方程解法比较简洁,构造一个 \(n+1\) 阶的类单位矩阵即可。但实现梯度下降解法则会遇到一个问题:\(\theta_0\) 的更新与 \(\theta_j\) 不同步,需要分开计算。
下面以 Coursera 上的二分类数据集 ex2data2.txt 为例,首先看一下数据的分布,代码同上一篇:
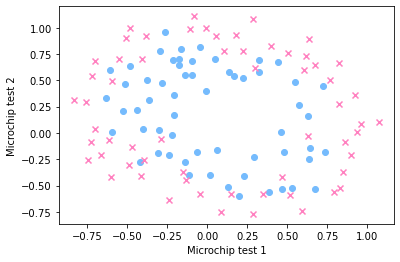
显然,需要引入多项式特征实现高次的曲线,这里将数据的两维都扩充为 \(6\) 次,形成有 \(28\) 维特征的数据,沿用上一篇的矩阵运算,实现逻辑回归如下:
1 | |
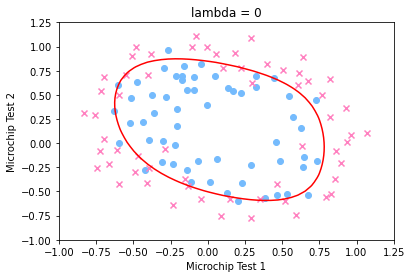
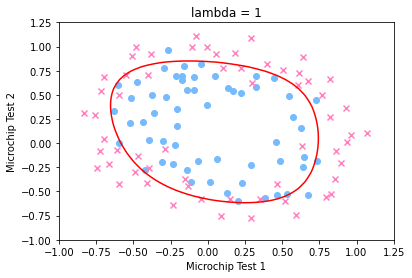
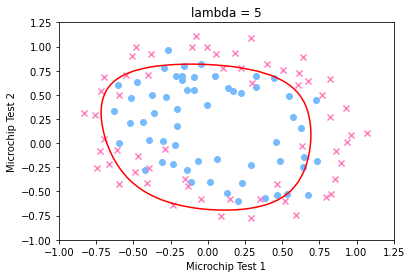
分别绘制出 \(\lambda=0,1,5\) 时的决策边界图如下: