ML学习笔记 #12 异常检测
本文最后更新于:2022年12月5日 下午
本文介绍机器学习的一种应用——异常检测(Anomaly Detection)。异常检测是一类经典的生成式(Generative)任务,和朴素贝叶斯分类器有点类似,都需要先建模已有样本的分布。但异常检测的特点在于其假设样本特征服从高斯分布(Gaussian Distribution),而异常样本就是出现概率极小的 \(3\sigma\) 外的点,因此可以无监督学习。
异常检测 | Anomaly Detection
异常检测的应用情景十分广泛:从工业产品的质量检测、银行用户的欺诈检测、集群的设备异常检测,都可以应用。其特点是:异常点通常偏离正常数据,且可能性较低。
传统的异常检测通过手工选择特征,并假设这些特征都服从高斯分布(正态分布)\(x \sim N(\mu, \sigma^2)\),则其概率密度函数: \[ P(x;\mu ,\sigma ^2)=\frac{1}{\sqrt{2\pi}\sigma}\exp \left( -\frac{(x-\mu )^2}{2\sigma ^2} \right) \] 其中:
- \(\mu\) 是样本均值,代表分布的中心;
- \(\sigma^2\) 是样本方差,代表样本偏离中心的程度,\(\sigma\) 越小,概率密度曲线就越瘦高;
- 概率密度函数满足:\(\int_{-\infty}^{+\infty}{P(x;\mu ,\sigma ^2)\mathrm{d}x}=1\)。
多元高斯分布
一个样本往往含有多个特征,多个特征组成的分布就是多元高斯分布(Multivariate Gaussian Distribution)。通常,我们朴素地假设 \(x\) 的各个特征维度互不相关,则联合概率密度函数等于各分量的概率密度函数之积,即: \[ \begin{aligned} P\left( x;\mu ,\Sigma \right) &=\prod_{i=1}^n{P\left( x_i;\mu _i,\sigma _{i}^{2} \right)}\\ &=\frac{1}{\left( 2\pi \right) ^{n/2}\prod_{i=1}^n{\sigma _i}}\exp \left( -\frac{1}{2}\sum_{i=1}^n{\frac{\left( x_i-\mu _i \right) ^2}{\sigma _i^2}} \right)\\ \end{aligned} \] 而对于其中的指数部分,可以表示为矩阵乘法的形式: \[ \begin{aligned} \xi ^2(x,\mu ,\sigma )&=\sum_{i=1}^n{\left( \frac{x_i-\mu _i}{\sigma _i} \right) ^2}\\ &=\sum_{j=i}^n{\left( x_i-\mu _i \right)}\left( x_i-\mu _i \right) \left( \frac{1}{\sigma _i} \right) ^2\\ &=\left[ x_1-\mu _1,x_2-\mu _2,\cdots ,x_n-\mu _n \right] \left[ \begin{matrix} \frac{1}{\sigma ^2}& 0& \cdots& 0\\ 0& \frac{1}{\sigma ^2}& \cdots& 0\\ \vdots& \vdots& \ddots& \vdots\\ 0& 0& \cdots& \frac{1}{\sigma ^2}\\ \end{matrix} \right] \left[ \begin{array}{c} x_1-\mu _1\\ x_2-\mu _2\\ \vdots\\ x_n-\mu _n\\ \end{array} \right]\\ &=(x-\mu )^T\Sigma ^{-1}(x-\mu )\\ \end{aligned} \] 其中根据 \(x_i\) 相互独立知: \[ \begin{aligned} \Sigma &=\mathbb{E} \left\{ (x-\mathbb{E} x)(x-\mathbb{E} x)^T \right\}\\ &=\left[ \begin{matrix} \mathrm{var}\left( x_1 \right)& \mathrm{cov}\left( x_1,x_2 \right)& \cdots& \mathrm{cov}\left( x_1,x_n \right)\\ \mathrm{cov}\left( x_2,x_1 \right)& \mathrm{var}\left( x_2 \right)& \cdots& \mathrm{cov}\left( x_2,x_n \right)\\ \vdots& \vdots& \ddots& \vdots\\ \mathrm{cov}\left( x_n,x_1 \right)& \mathrm{cov}\left( x_n,x_2 \right)& \cdots& \mathrm{var}\left( x_n \right)\\ \end{matrix} \right]\\ &=\left[ \begin{matrix} \sigma ^2& 0& \cdots& 0\\ 0& \sigma ^2& \cdots& 0\\ \vdots& \vdots& \ddots& \vdots\\ 0& 0& \cdots& \sigma ^2\\ \end{matrix} \right]\\ \end{aligned} \] 从而得到多元正态分布的概率密度函数: \[ P(x;\mu ,\Sigma )=\frac{1}{(2\pi )^{n/2}|\Sigma |^{1/2}}\exp \left( -\frac{1}{2}(x-\mu )^T\Sigma ^{-1}(x-\mu ) \right) \] 其中,\(x\in\mathbb R^n\) 是 \(n\) 维随机变量,\(\mu\in\mathbb R^n\) 是 \(x\) 的均值,\(\Sigma\in\mathbb R^{n\times n}\) 是协方差矩阵。
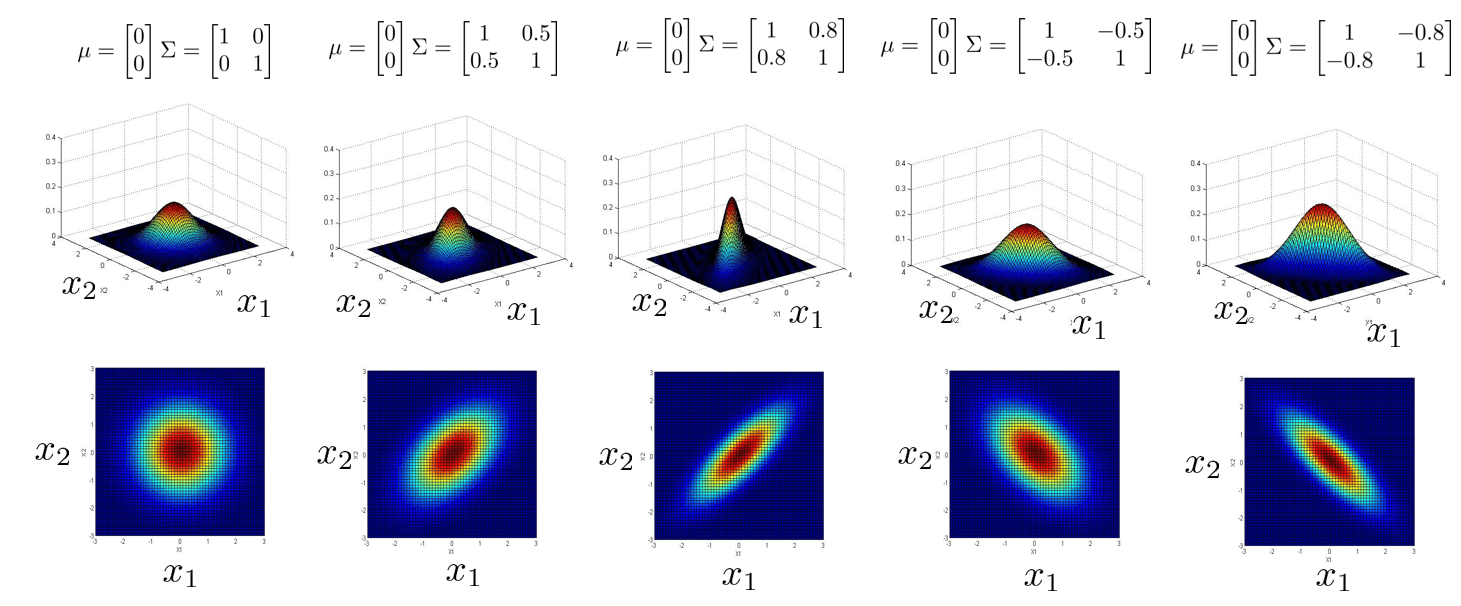
该式子在各变量不独立时也成立,因此这里的协方差矩阵,不一定是上述的对角矩阵形式!此处只是乱证。
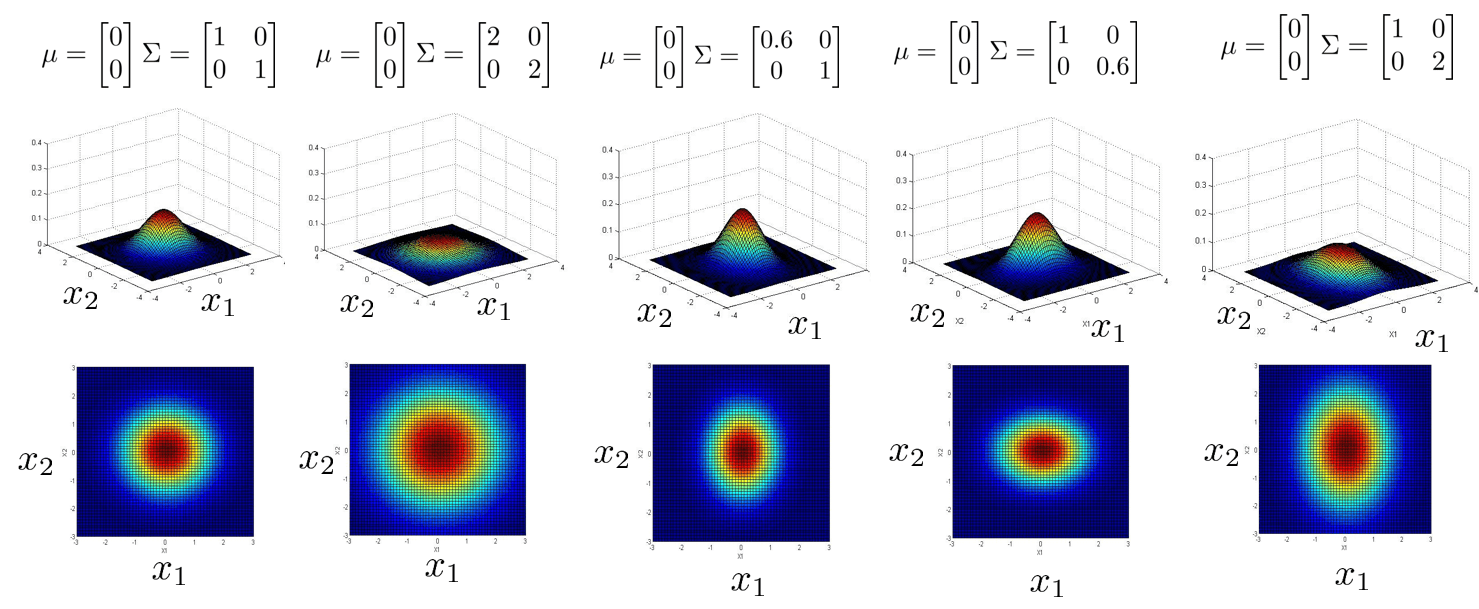
下面我们用一组图来展示协方差矩阵对多元高斯分布的影响:
问题描述
异常检测的原理非常简单:假设有正常的数据集 \(\{x^{(1)},x^{(2)},\ldots,x^{(m)}\}\),我们构建一个多元正态分布,其均值为样本均值,协方差矩阵为样本的协方差矩阵,即: \[ \begin{aligned} \mu &=\frac{1}{m}\sum_{i=1}^m{x^{(i)}}\\ \Sigma &=\frac{1}{m}\sum_{i=1}^m{(}x^{(i)}-\mu )(x^{(i)}-\mu )^T\\ P(x;\mu ,\Sigma )&=\frac{1}{(2\pi )^{n/2}|\Sigma |^{1/2}}\exp \left( -\frac{1}{2}(x-\mu )^T\Sigma ^{-1}(x-\mu ) \right)\\ \end{aligned} \] 或者直接认定 \(x\) 各维度不相关,取: \[ P(x;\mu ,\Sigma )=\prod_{i=1}^n{P}(x_i;\mu _i,\sigma _{i}^{2}) \]
前者能够自动捕捉特征之间的相关性,但计算代价较高,且通常需要 \(m>10n\),否则协方差矩阵 \(\Sigma\) 不可逆。
后者不能捕捉特征之间的相关性,但在计算上更快,且允许 \(m\leqslant n\) 的情况。
对于要检测的数据 \(x\),如果 \(P(x;\mu,\Sigma)\) 小于某个阈值 \(\varepsilon\),那么就认为该数据是异常数据,否则正常。
开发异常检测系统
特征选择
异常检测假设特征符合高斯分布,如果数据的分布不是高斯分布,我们通常先将数据转换成高斯分布。通常需要先画出特征分布的直方图,如果数据呈现偏态分布(Skewed Distribution):
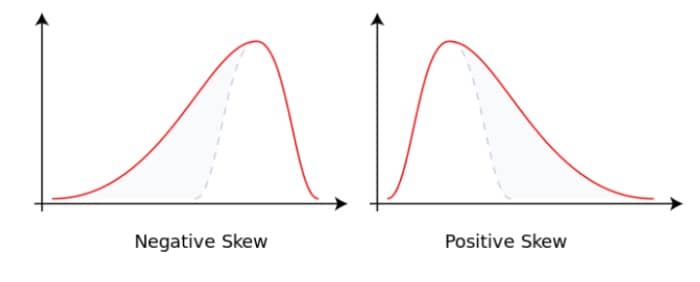
常用的转换方式有:对数变换、指数(平方根、倒数)变换、正反旋变换等。
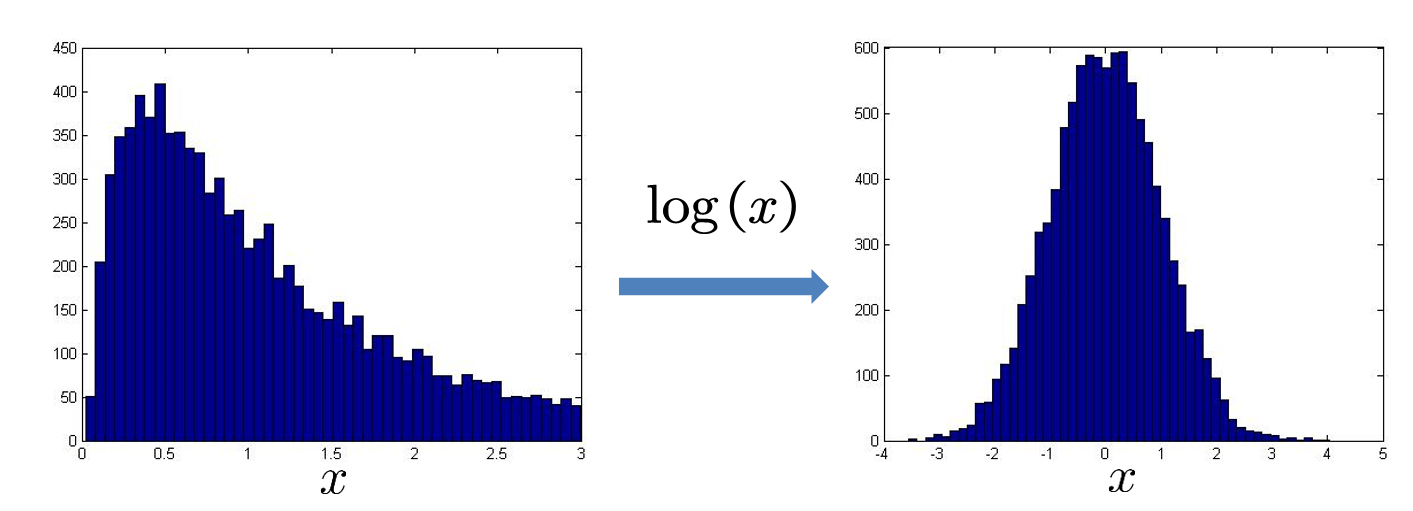
训练和验证
如果我们有标注过的数据(标注是否异常),则可以将数据划分为训练集、验证集和测试集。
- 训练集包含大部分正常数据,并据此构建出正态分布模型;
- 验证集和测试集包含正常和异常数据;
- 根据验证集的结果调整参数 \(\varepsilon\),最后在测试集上进行测试。
此外,由于异常检测数据集通常分布不均(正常数据远远多于异常数据),所以实验指标应该取 \(\text{Precision},\text{Recall},\text{F1}\) 等值。
误差分析
在通过上述流程后,如果模型效果仍然不好,则需要进行误差分析。
一个常见的问题是:一些异常的数据可能也会有较高的 \(P(x)\) 值,从而被算法认为是正常的。这种情况下我们应该去分析那些被算法错误预测的数据,观察其特征的选择是否存在问题。考虑更换特征、或将已有的特征进行组合以获取更好的特征。
代码实现
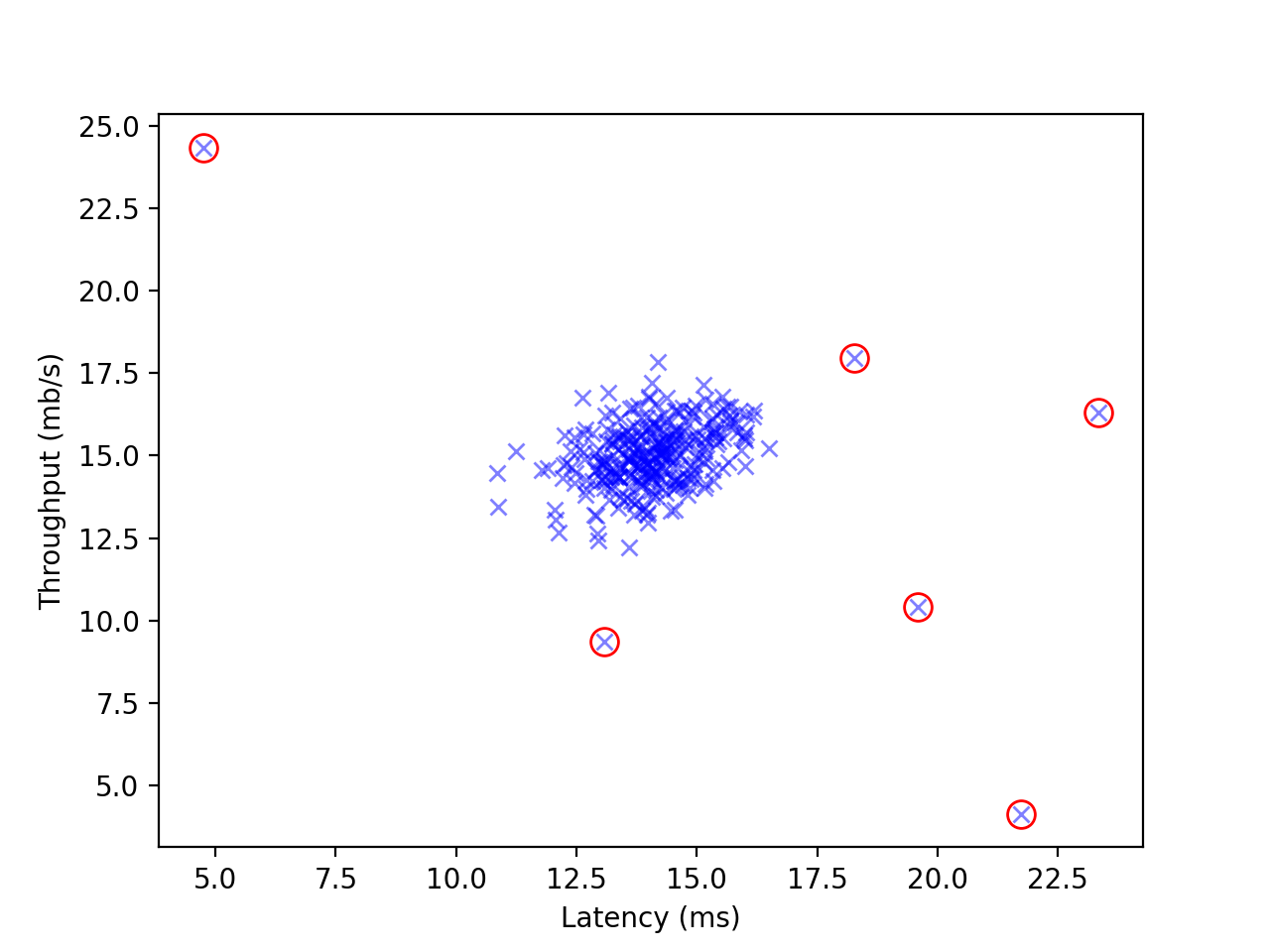
下面以 Coursera 上的数据集 ex8data1.mat 为例,这是一个二维平面上的点集,包含无标注的训练集和有标注的的测试集。这里采用 Scipy 科学计算库中的多元正态分布方法,将测试集再划分出验证集,使用如下代码:
1 | |
根据验证集找到的最佳 \(\varepsilon\) 约为:\(2.72\times 10^{-5}\);此时测试集上 \(\text{F1}\) 值约为:\(0.98\).